
Definition
Chaos Engineering - What is it ?
By definition from Gremlin site: „Chaos Engineering is a disciplined approach to identifying failures before they become outages. By proactively testing how a system responds under stress, you can identify and fix failures before they end up in the news”
Principles for Chaos Engineering
Plan an experiment
Create a hypothesis, plan, test scenarios. What could go wrong? How can we avoid it ?
Test it
Execute the smallest tests that will teach us something and allow to be better prepared
Review results & investigate
Find an issue? Job well done! Review the results, investigate any failures, provide feedback and guidance
How does Chaos Engineering work ?
Chaos engineering begins with analyzing the expected behavior of a software system. Here are the steps involved in implementing chaos experiments.
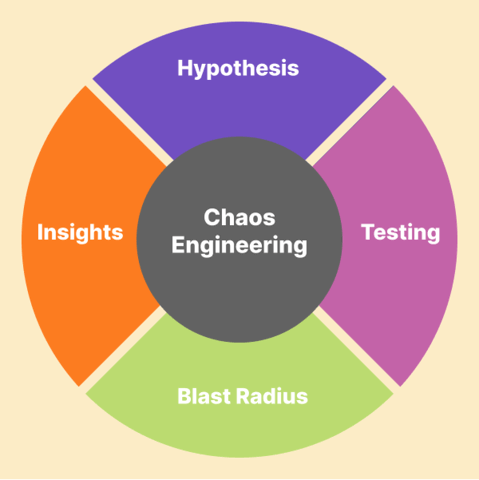
Hypothesis:
When engineers change a variable, they ask themselves what should happen. They assume that services will continue uninterrupted if they terminate them randomly. A hypothesis consists of a question and an assumption
Testing:
Engineers use simulated uncertainty, load testing, and network and device monitoring to test their hypothesis. A failure in the stack breaks the hypothesis.
Blast Radius:
Using failure analysis, engineers can learn what happens under unstable cloud conditions. A test’s effect is known as its ‘blast radius.’ Chaos engineers can manipulate the blast radius by controlling the tests.
Insights:
It helps make software and microservices more resilient to tackle unforeseeable events.
Customer requirements
Meet with customers (Application Teams) to collect information what are the requirements from customer side and what is most important for them in terms of destructive testing.
Types of experiments in Chaos Engineering
Here are the types of experiments in Chaos Engineering.
Dependency testing
Most times, chaos engineers assume a happy scenario for the software development process after conducting standard tests. However, this step backfires sometimes, especially when there are many dependencies.
Therefore, Chaos Engineers must conduct thorough tests and check hidden dependencies between microservices, reddis, database, memcached, and downstream services. By doing such tests and checks, they can understand the challenges that may cause failure in the production and post-production stages.
Inject failure
Inject a failure or something that can cause your software to behave differently is essential for Chaos Engineering. With this experiment, engineers can discover weaknesses or vulnerable components of the software, and build something to keep the software running when a particular component malfunctions.
Automate faults
After coming across different faults while checking the reliability of the system, engineers use site reliability engineering to try and fix faults automatically. With such automation, they check which automatic solutions work and for which functions they need to build backup components.
How to implement
Good reason to implement it as part of Continuous Integration / Continuous Deployment
Most recent cases of PROD issues
- Network: blackholes, retransmissions, saturation, routing loop
- Databases: Caches / wrong SQL injection, unavailability
- Middleware: failure of MQ, AQM, PubSub
- Hardware: failure of memory / CPU / network interfaces
Chaos Engineering requirements
Chaos Engineering as extension of destructive tests you can provide to customers
Application infrastructure should be Chaos Engineering compliant (more than 1 pod, etc.)
Need to build framework / toolkit:
- Use existing opensource tools like (Chaos Monkey, Pumba, Powerfulseal, Kube-Monkey, etc.)
- Consolidate existing tools in one tool (if possible)
UNKNOWNS:
- Can be as part of CI/CD/Standalone ?
- Where to test ? Chaos Engineering executed on DEV environment or maybe PROD ?
- What permissions needed? We must think about this in terms of testing it:
• On a GKE Cluster ?
• On GCE ?
• Across Folders in GCP ?
• Do we need a dedicated environment/cluster for this?
Chaos Engineering Toolkits
From the list of available toolkits on the market you can pickup a lot. Including opensource editions as well as commercial ones.
Examples of Test scenarios
CPU saturation
Create chaos engineering experiments with CPU load. The goal of this scenario is to verify what is the impact on the application during the period of time when CPU is filled on the VM/Pod hosting the application.
Memory saturation
Create chaos engineering experiments with memory load. The goal of this scenario is to verify what is the impact on the application during the period of time when RAM is filled on the VM/POD hosting the application.
Network delay, drop, corrupt, loss
Series of network experiments where you can inject delay / loss / corrupt between two host exchanging traffic. Useful when you want to simulate latency between application and call making to low level services.
High disk space utilization (I/O) or disk runs out of space
When you want to stress your disk (I/O operations) or make 100% disk full this is experiment you can inject. It will tell you how your application behaves when there is no space available on a disk !
DB (MySQL/MongoDB) injections
Stressing database is possible by injecting delays in “inserts”, “selects” or “updates”
VM / POD / Container restart / delete
If you want to see how your application will survive (if any) you may wish to shutdown VM instance or delete pod/container on the cloud (GKE)
Process kill
Killing process on VM (POD if application runs in the Kubernetes) is a test for your application if that process can be easily respawn and will connect to all components.
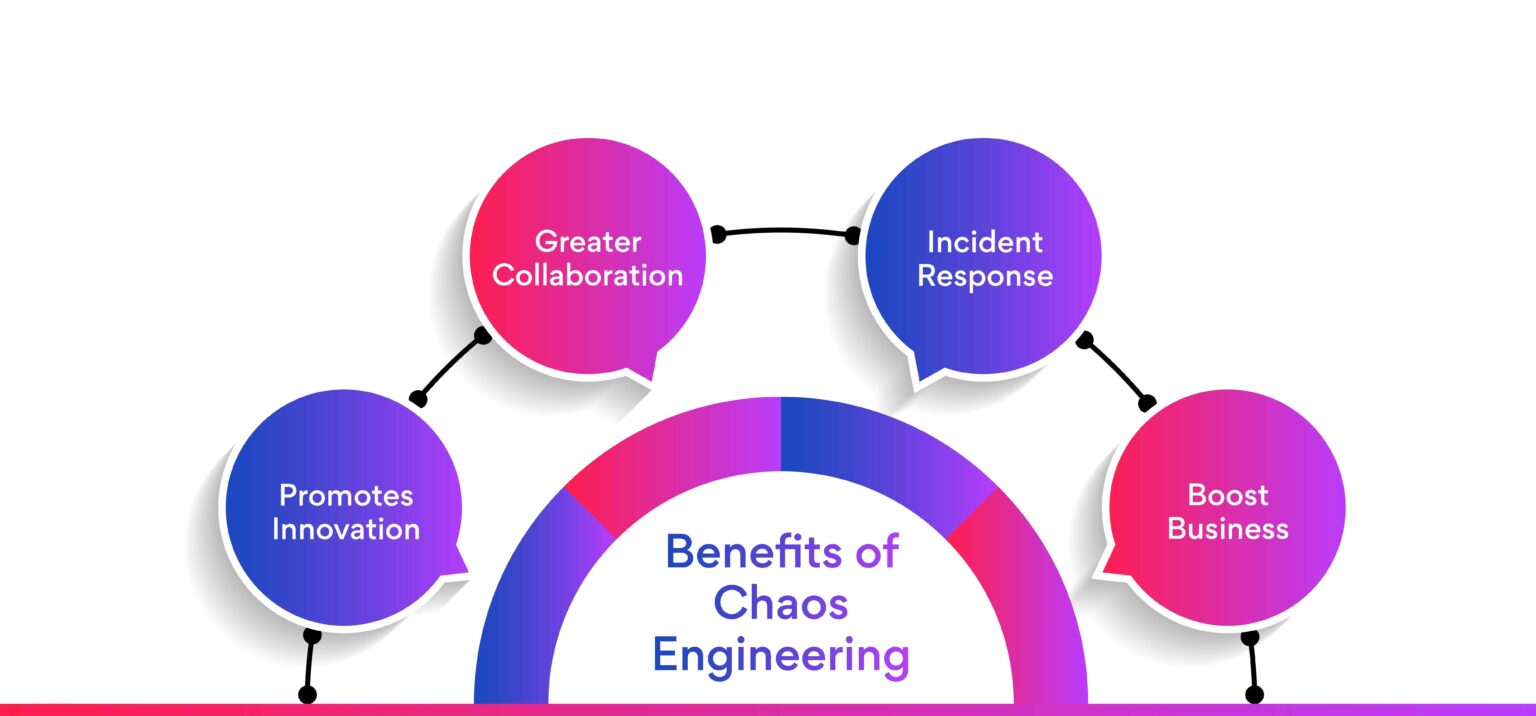
What are the benefits of Chaos Engineering?
The benefits of Chaos Engineering include:
Promotes innovation
Chaos Engineering promotes innovation by identifying design and structural flaws in the software system. The intelligence gathered from understanding structural and design flaws helps improve new and existing components.
Greater collaboration
Chaos Engineering facilitates greater collaboration, as the insights gathered are not limited to chaos engineers but get shared across different departments.
Streamlines incident response
Incident response is important for applications that need to run all the time. By testing variables and components in advance, Chaos Engineering helps streamline troubleshooting, repairs, and incident response.
Boosts business
Organizations that use Chaos Engineering can build resilient and reliable systems that increase customer satisfaction. Also, these resilient software applications can boost business demand by producing less failure-prone software.
Author: Pablo